Scrapy to najlepsze i najbardziej elastyczne narzędzie do web scrapingu z jakim się do tej pory spotkałem. Szybkość tworzenia skryptów w dużej mierze zależy od struktury analizowanej strony, zastosowanych zabezpieczeń przeciw botom oraz ilości pobieranych danych. W standardowych przypadkach stworzenie i wdrożenie web scrapera może zająć dosłownie 15 minut. Wpis ten jest krótkim tutorialem wprowadzającym do narzędzia. Pokażę jak stworzyć prosty web scraper (na przykładzie popularnego serwisu ogłoszeniowego) oraz jak za pomocą serwisu Scrapinghub wdrożyć skrypt tak aby wykonywał się cyklicznie.
Przykładowy kod do tego wpisu dostępny jest na moim GitHubie.
# Lista bibliotek z których korzystam:
# pip install scrapy
conda install -c conda-forge scrapy # preferowane
pip install shub # klient scrapinghubDlaczego Scrapy?
- open source
- praca na projektach do których można tworzyć szablony
- rozszerzenia ułatwiające omijanie zabezpieczeń przeciw botom:
- rotacja user agenta
- rotacja proxy
- symulacja przeglądarki poprzez Selenium lub Splash
- rotacja user agenta
- łatwa integracja z zewnętrznymi bazami danych
- szybkie i proste wdrożenie:
- scrapyd - prywatny serwer
- Scrapinghub - chmura
- scrapyd - prywatny serwer
Standardowo dostępny jest jeden szablon dla projektu oraz cztery szablony scraperów. Z czasem można dodawać własne szablony, dzięki czemu ogromna część pracy może zostać zastąpiona zaledwie dwoma komendami (scrapy startproject oraz scrapy genspider).
Scrapy jest bardzo popularnym narzędziem, dlatego w internecie można znaleźć niejeden (lepszy) tutorial. Celem tego wpisu jest przede wszystkim pokazanie tego jak (szybko) zrobić projekt od stworzenia scrapera po jego wdrożenie. Wszystkich zainteresowanych lepszym poznaniem narzędzia odsyłam m.in. do dokumendacji.
[AKTUALIZACJA - marzec 2020]
Wpis ma charakter edukacyjny, dlatego proszę o korzystanie z omówionych tutaj skryptów z rozwagą. Używanie web scraperów bez zastanowienia może doprowadzić do zablokowania waszego IP - w konsekwencji nie tylko wy, ale wasi domownicy, czy współpracownicy mogą utracić dostęp do stron z których korzystacie na codzień (np. sklep internetowy, czy serwis ogłoszeniowy). Do tego wpisu wybrałem serwis Otodom, ale mogłem wybrać każdy inny. Na dzień dzisiejszy serwis ten blokuje IP Scrapinghuba, dlatego do pełnego sukcesu byłyby potrzebne dodatkowe działania (jak np. proxy lub integracja z Crawlera = koszty).
KROK 1. WEB SCRAPER
Z poziomu terminala wykonuję poniższy kod:
scrapy startproject otodom_scraper
cd otodom_scraper
scrapy genspider -t crawl crawl_ads_basic otodom.plPrzygotowałem właśnie wszystkie niezbędne pliki do pracy. Z mojej perspektywy najbardziej interesujące są pliki crawl_ads_basic.py, który zawiera strukturę scrapera oraz items.py, który zawiera strukturę danych wyjściowych.
+-- scrapy.cfg
+-- setup.py
+-- otodom_scraper
| +-- spiders
| +-- crawl_ads_basic.py
| +-- settings.py
| +-- items.py
| +-- middlewares.py
| +-- pipelines.pyW przypadku pobierania treści ze stron ważne jest stosowanie dobrych praktyk. Jedną z nich jest stosowanie opóźnienia, aby nadmiernie nie wykorzystywać serwera (i nie zablokować sobie IP). Do ustawienia opóźnienia służy opcja DOWNLOAD_DELAY dostępna w pliku settings.py.
Przy tworzeniu skryptu skupiłem się na pobieraniu ogłoszeń dotyczących sprzedaży mieszkań. Jedynie lokalizację mieszkania poddałem parametryzacji (parametr locations). Aby parametryzacja lokalizacji działała poprawnie, napisałem funkcję usuwającą znaki diakrytyczne.
def remove_diacritics(input_str):
nfkd_form = unicodedata.normalize('NFKD', input_str.replace('ł', 'l'))
return u''.join([c for c in nfkd_form if not unicodedata.combining(c)])
# remove_diacritics('zażółć gęślą jaźń')class CrawlAdsBasicSpider(CrawlSpider):
name = 'crawl_ads_basic'
allowed_domains = ['otodom.pl']
def __init__(self,
locations=None,
*args, **kwargs):
if locations:
self.locations = remove_diacritics(locations).replace(' ', '-').split(';')
self.locations = [x + '/' for x in self.locations]
else:
self.locations = ['']
url_parts = ['/sprzedaz/mieszkanie/' + x for x in self.locations]
...Wybrałem podejście web crawlingu. Oznacza to, że po stronie poruszam się definiując reguły nałożone na odnalezione linki. allowed_domains określa akceptowalne domeny spośród adresów startowych. start_urls określa adresy od których zacznie się przeszukiwanie strony. rules określa reguły według, których są wybierane linki podczas nawigowania po stronie. W tym przypadku chcę poruszać się po stronach zawierających listę ofert dla wybranych lokalizacji. Na odfiltrowanych linkach skrypt generuje zapytanie i przekazuje odpowiedź do funkcji parse_item.
...
self.start_urls = ['https://www.otodom.pl' + x + '?nrAdsPerPage=72' for x in url_parts]
self.rules = (
Rule(LinkExtractor(allow=[x + '\\?nrAdsPerPage=72$' for x in url_parts]),
callback='parse_item', follow=True),
Rule(LinkExtractor(allow=[x + '.*page=[0-9]+$' for x in url_parts]),
callback='parse_item', follow=True),
)Przygotowuję strukturę wyników w pliku items.py.
def filter_spaces(value):
return value.strip()
def clean_price(value):
return ''.join(re.findall('[0-9]+', value))
class AdItem(scrapy.Item):
item_id = scrapy.Field(
input_processor=MapCompose(filter_spaces),
output_processor=TakeFirst(),
)
tracking_id = scrapy.Field(
input_processor=MapCompose(filter_spaces),
output_processor=TakeFirst(),
)
url = scrapy.Field(
input_processor=MapCompose(filter_spaces),
output_processor=TakeFirst(),
)
featured_name = scrapy.Field(
input_processor=MapCompose(filter_spaces),
output_processor=TakeFirst(),
)
title = scrapy.Field(
input_processor=MapCompose(filter_spaces),
output_processor=TakeFirst(),
)
subtitle = scrapy.Field(
input_processor=MapCompose(filter_spaces),
output_processor=TakeFirst(),
)
rooms = scrapy.Field(
input_processor=MapCompose(filter_spaces),
output_processor=TakeFirst(),
)
price = scrapy.Field(
input_processor=MapCompose(clean_price),
output_processor=TakeFirst(),
)
price_per_m = scrapy.Field(
input_processor=MapCompose(clean_price),
output_processor=TakeFirst(),
)
area = scrapy.Field(
input_processor=MapCompose(filter_spaces),
output_processor=TakeFirst(),
)
others = scrapy.Field(
input_processor=MapCompose(filter_spaces),
output_processor=Join(),
)W dużym uproszczeniu: tworzę klasę AdItem, w której definuję pola wynikowe (np. title jako tytuł ogłoszenia). Każde z tych pól można obłożyć funkcjami czyszczącymi dane. Przykładowo, jeżeli wprowadzę cenę mieszkania jako listę ['100 000 PLN', '1 zł'], to input_processor przetworzy mi listę do postaci ['100000', '1'], natomiast output_processor zwróci wynik jako pierwszy z listy tzn. '100000'.
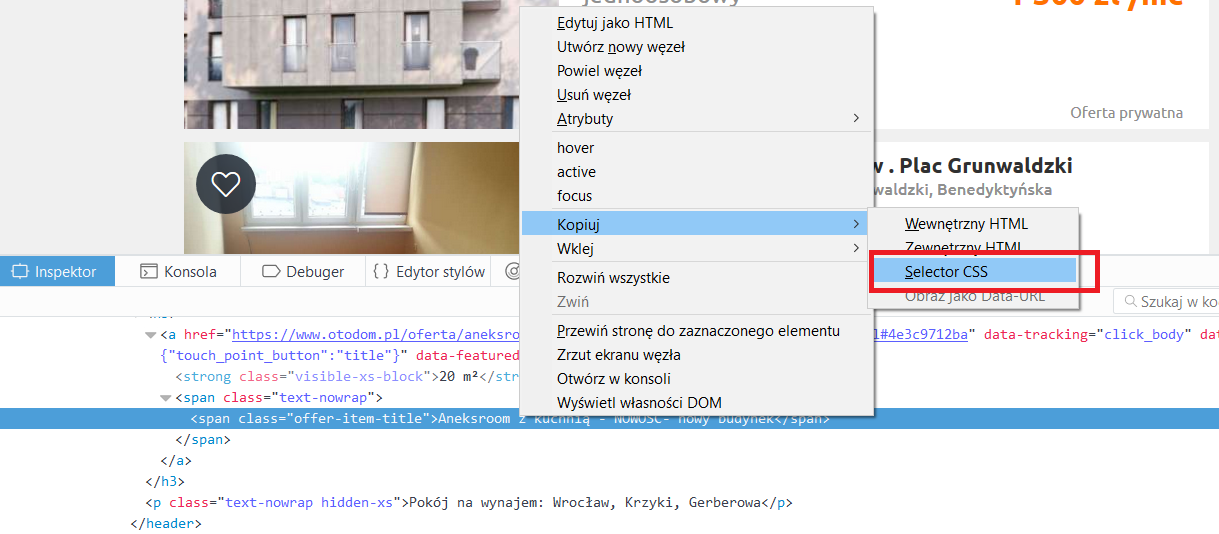
W pliku crawl_ads_basic.py pozostało napisanie funkcji ekstrahującej dane z listy ogłoszeń. Przechodzę po każdym elemencie listy i za pomocą selektorów css wyciągam interesujące mnie wartości Nie przejmuję się oczyszczaniem danych, bo jest to już zaprogramowane w klasie AdItem. Wyekstrahowane dane przechwytywane są one przez pipeline i domyślnie zwracane w konsoli. Polecam zaglądnąć do pliku settings.py - są opcje aby te wyniki zapisywać do plików w formacie, csv, json, czy xml.
def parse_item(self, response):
for ad in response.css('.col-md-content article'):
item = ItemLoader(item=AdItem(), selector=ad)
item.add_css('item_id', '::attr("data-item-id")')
item.add_css('tracking_id', '::attr("data-tracking-id")')
item.add_css('url', '::attr("data-url")')
item.add_css('featured_name', '::attr("data-featured-name")')
item.add_css('title', '.offer-item-title ::text')
item.add_css('subtitle', '.offer-item-header p ::text')
item.add_css('rooms', '.offer-item-rooms ::text')
item.add_css('price', '.offer-item-price ::text')
item.add_css('price_per_m', '.offer-item-price-per-m ::text')
item.add_css('area', '.offer-item-area ::text')
item.add_css('others', '.params-small li ::text')
yield item.load_item()Bardzo przydatne z punktu widzenia powyższego są narzędzia deweloperskie przeglądarek internetowych. Za pomocą kilku kliknięć można uzyskać informacje o ścieżce do wybranego elementu.
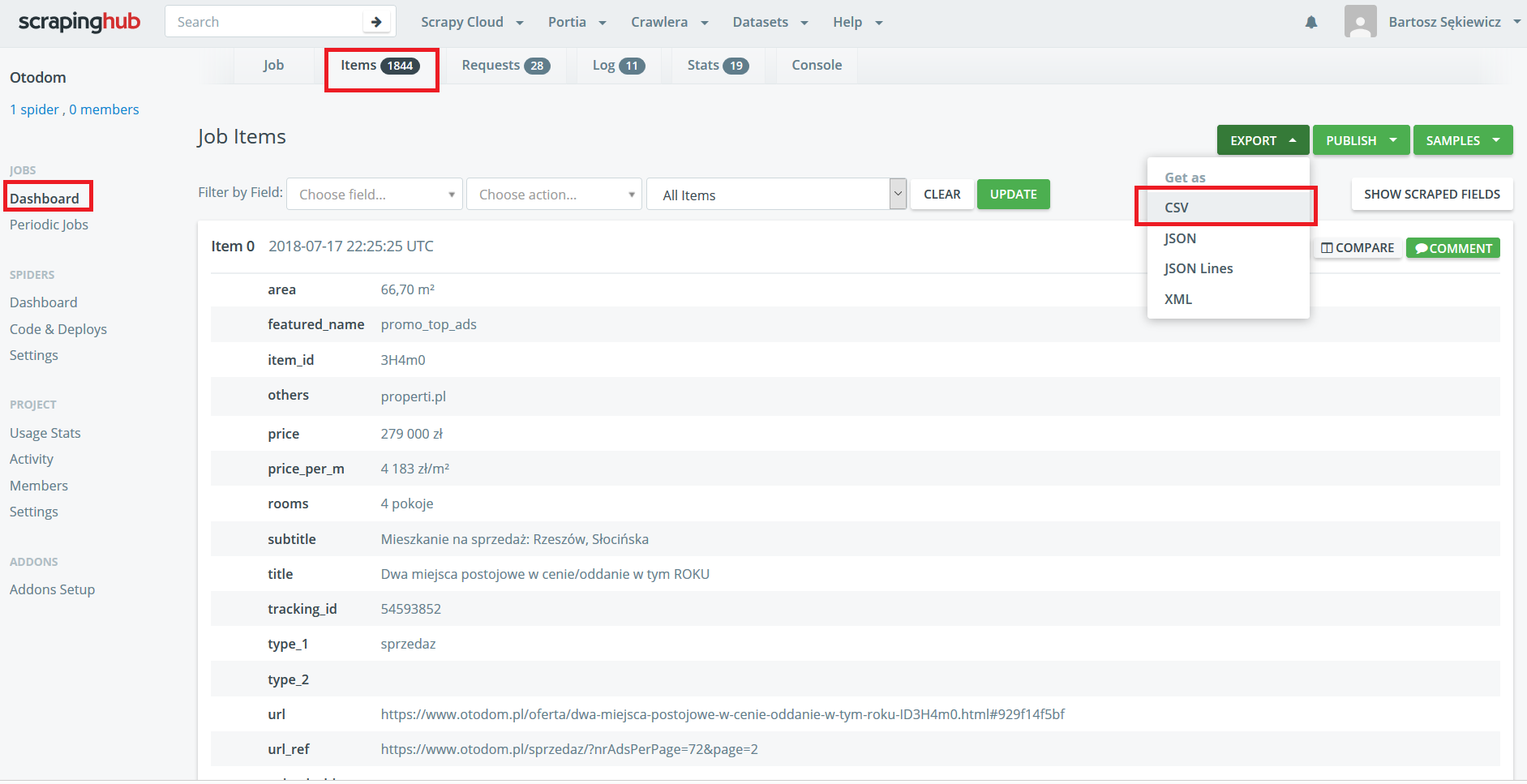
W zasadzie to tyle. Scraper można jeszcze przetestować wpisując scrapy crawl crawl_ads_basic - pobrane dane powinny wyświetlać się na konsoli. Wpisując scrapy crawl crawl_ads_basic -o sciezka/plik można przekierować wyniki do wybranego pliku (domyślnie w formacie json). Aby ustawić własne wartości parametrów należy skorzystać z przełącznika -a (na przykład: scrapy crawl crawl_ads_basic -a locations=kraków;skawina). Udostępniam też próbkę z danych, które udało mi się pobrać.
KROK 2. WDROŻENIE
Często są sytuacje, że jakieś dane muszą być pobierane w miarę regularnie. Mając gotowy skrypt można użyć Windowsowego Menadżera zadań albo Linuxowego CRONa. Pytanie co w sytuacjach, gdy dane muszą być pobierane bardzo często? Komputer uruchomiony 24h/dobę? A jak będziemy chcieli zagrać np. w Wiedźmina 3 wykorzystując zasoby komputera do granic możliwości albo po prostu zabraknie prądu? W takich sytuacjach najlepiej mieć własny serwer, ale to kosztuje.
W przypadku Scrapy’ego można skorzystać ze Scrapinghub! Serwis daje możliwość odpalania własnego scrapera za darmo (niestety po zamianach w 2019 roku, jedynie jedna godzina miesięcznie i kilkudniowy czas retencji danych). Niemniej jednak dla małych domowych projektów to wysatrcza.
Proces wdrożenia scrapera jest prosty. Na początek trzeba założyć konto w serwisie (można to zrobić jednym kliknięciem podpinając się pod Google+, lub GitHuba). Następnie należy utworzyć nowy projekt i wygenerować klucz API, aby było możliwe wysłanie kodu z poziomu terminala.
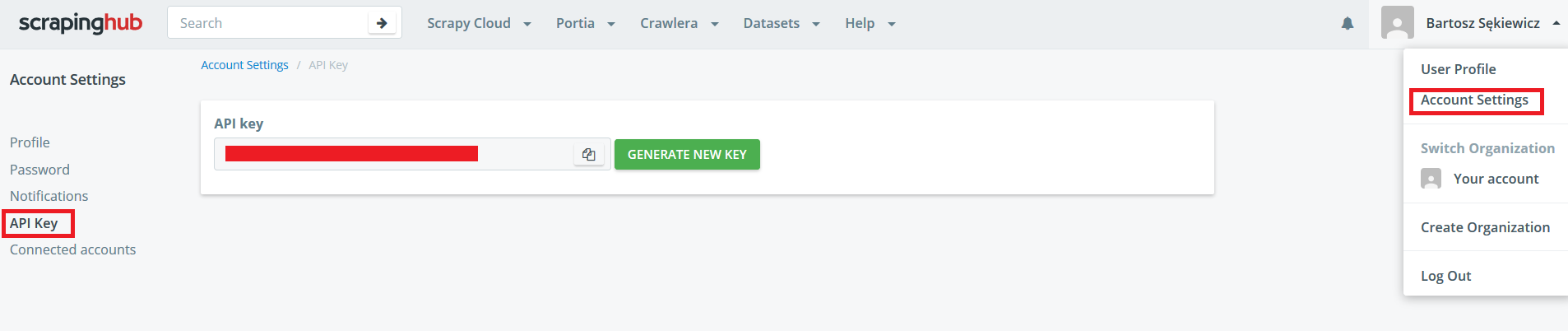
Skrypty wysyłam do chmury za pomocą biblioteki shub (pip install shub).
shub login
# API key: api_key
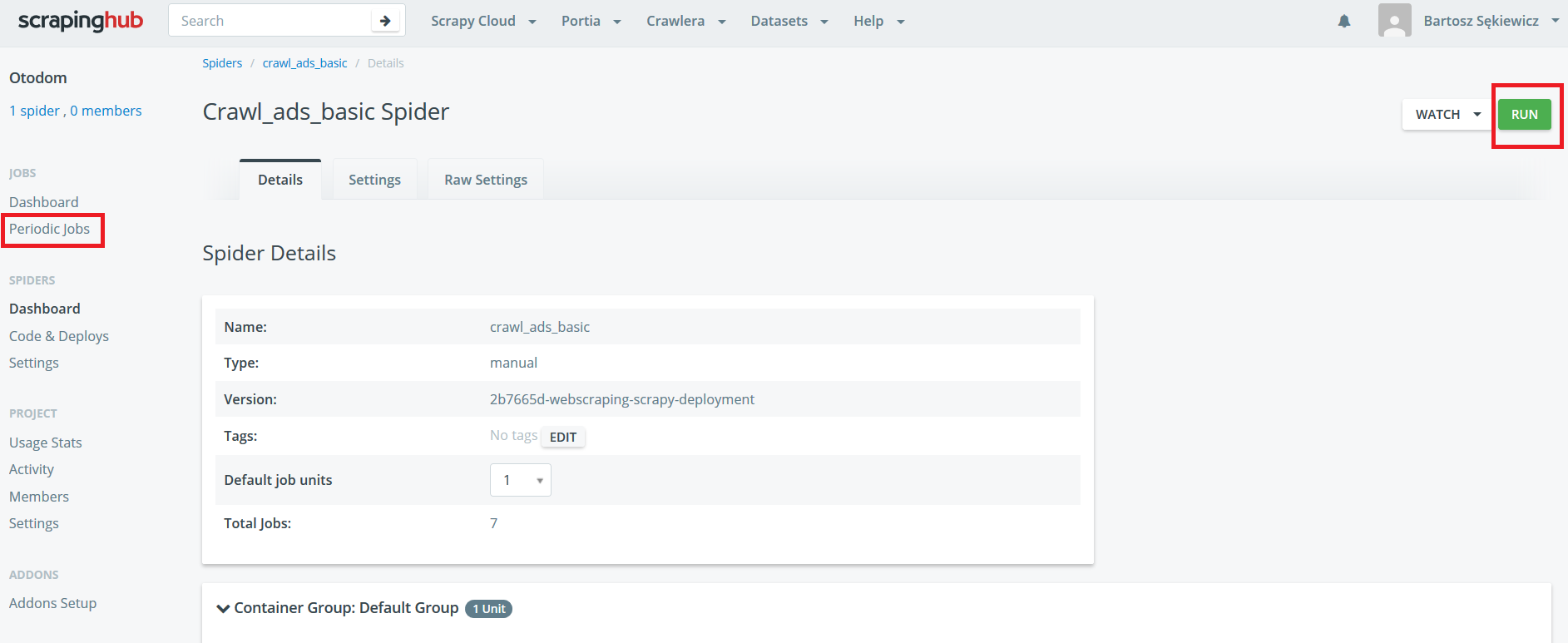
shub deploy project_idPo chwili skrypt jest już w projekcie i można go odpalać!
Pobranie danych to jedno kliknięcie!