Pobieraniem treści ze stron internetowych (web scrapingiem) zajmuję się komercyjnie od kilku lat. Wykorzystuję do tego m.in. Bash, VBA, Google Sheets, R oraz Python. W ostatnim czasie, podczas konferencji WhyR? 2017 oraz DATA SCIENCE? AGHree! 2018, miałem przyjemność prowadzić warsztaty z web scrapingu w R. W trakcie przygotowywania warsztatów natrafiłem na ciekawe zabezpieczenie przed automatycznym pobieraniem danych. W “serii” wpisów dotyczących web scrapingu chciałbym podzielić się wybranymi problemami z którymi przyszło mi się zmierzyć.
Przykładowy kod do tego wpisu dostępny jest na moim GitHubie.
# Lista pakietów z których korzystam:
require(magrittr) # pipe
require(rvest) # pobieranie danych ze stron internetowych
require(stringi) # obróbka tekstu
require(readr) # wczytywanie plików
require(magick) # obróbka obrazu
require(tesseract) # OCR
require(googledrive) # Google DriveW dzisiejszym wpisie zajmę się zabezpieczeniem zastosowanym na tej stronie. Na pierwszy rzut oka problem pobrania danych wygląda banalnie. Prosta tabela podzielona na kilka podstron. Liczbę wyników w tabeli można zwiększyć do 100. Do nawigacji pomiędzy kolejnymi podstronami wystarczy odpowiednia parametryzacja linku.
# pobieram zawartość strony
s <- paste0(
'https://www.analizy.pl/',
'fundusze/fundusze-inwestycyjne/notowania') %>%
html_session
# ekstrahuję dane z tabeli
notowania <- s %>%
# tabela z danymi jest klasy noteTable
# to jedyny taki element na stronie
html_node("#noteTable") %>%
# dwupoziomowy nagłówek
# wyrzucam pierwszy poziom
# drugi poziom staje się nagłówkiem
html_table(header = TRUE) %>%
.[,-1] %>%
set_colnames(.[1,]) %>%
# pierwsza kolumna to obrazek
# może być interesujący atrybut title
# aktualnie pomijam
.[-1,] %T>%
# podsumowanie
str| fundusz | data | j.u..netto | X1d | X1m | X3m | X12m | X36m | X60m | ytd | grupa | srri |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AGIO Agresywny Spółek Wzrostowych (AGIO SFIO) | 3.03 | NA | 0,00% | -4,78% | -0,6% | -3,6% | -19,7% | 0,3% | -2,9% | AKP_UN | 5/7 |
| AGIO Akcji Małych i Średnich Spółek (AGIO SFIO) | 3.03 | NA | 0,00% | -3,35% | 4,7% | 2,5% | 0,7% | AKP_MS | 4/7 | ||
| AGIO Akcji PLUS (AGIO PLUS FIO) | 2.03 | NA | 2,02% | -9,40% | -8,8% | -14,0% | -28,7% | -10,2% | AKP_UN | 5/7 | |
| AGIO Dochodowy PLUS (AGIO PLUS FIO) | 2.03 | NA | -0,01% | 0,18% | 0,6% | 2,1% | 0,4% | PDP_UN | 2/7 | ||
| AGIO Kapitał (AGIO SFIO) | 3.03 | NA | 0,00% | 0,12% | 0,6% | -0,3% | 6,4% | 12,3% | 0,3% | PDP_CO | 2/7 |
Udało się pobrać prawie wszystkie dane, za wyjątkiem kolumny j.u. netto. Dlaczego?!
…
Tak! Wartości w kolumnie j.u. netto reprezentowane są przez obrazki.
Na początku wydawało mi się, że sprawa jest beznadziejna - tzn. będzie potrzebne użycie jakiegoś zaawansowanego OCR’a albo wykorzystanie uczenia maszynowego do rozpoznawania obrazu. Po małym researchu na temat możliwości R okazało się, że rozwiązania dające dobre wyniki są dostępne bez większego zagłębiania się w tematykę konwersji obrazu do tekstu.
Wypróbowałem dwa popularne rozwiązania: open source’owy tesseract oraz dostępny dla każdego posiadacza konta na Gmailu, Google Drive. Dla każdego z tych rozwiązań dostępne są odpowiednie biblioteki w R, których instalacja (nawet pod Windowsem) jest szybka i przyjemna.
Zanim jednak przejdę dalej uzupełniam kolumnę j.u. netto o linki do obrazków.
notowania$`j.u. netto` <- s %>%
html_nodes("tbody img[alt*='kurs']") %>%
html_attr("src") %>%
paste0("https://www.analizy.pl", .)TESSERACT
Pakiet tesseract dostępny jest na GitHubie i aby go zainstalować należy użyć komendy install.packages("tesseract") (pod linuxem trzeba doinstalować dodatkowe biblioteki, ale wszystko jest objaśnione w źródle).
# ustawienia OCR - skupiam się na poszukiwaniu liczb
engine <-
tesseract(options =
list(tessedit_char_whitelist = " 0123456789,.",
tessedit_char_blacklist = "!?@#$%&*()<>_-+=/:;'\"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz\n\t\r",
classify_bln_numeric_mode = "1"))
# oczyszczanie tekstu
text_clearing <- function(x) {
x %>%
stri_replace_all_regex("[ \n]", "") %>%
stri_replace_all_regex("[,]+", ".") %>%
stri_extract_first_regex('[0-9]+[//.]{0,1}[0-9]{0,2}') %>%
as.numeric %>%
format(2)
}# przykładowa konwersja obrazka
notowania[['j.u. netto']][1] %>%
image_read %>%
ocr(engine) %>%
text_clearing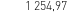 (obraz) vs 1254.97 (OCR)
(obraz) vs 1254.97 (OCR)
ZADZIAŁAŁO!!!
[AKTUALIZACJA - marzec 2020]
Gdy publikowałem ten post w 2018 roku, biblioteka tesseract nie zadziałała od razu tak dobrze jak teraz. Aby uzyskać dobre wyniki potrzebna była zmiana rozmiaru obrazka (o 30%) za pomocą funkcji image_resize z biblioteki magick. Jak widać narzędzie to jest ciągle udoskonalane (ale nadal nie jest idealne).
Poniżej wyniki dla pierwszych dziesięciu obrazków:
(obraz) vs 1254.97 (OCR)
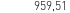 (obraz) vs 959.51 (OCR)
(obraz) vs 959.51 (OCR)
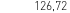 (obraz) vs 126.72 (OCR)
(obraz) vs 126.72 (OCR)
 (obraz) vs 104.24 (OCR)
(obraz) vs 104.24 (OCR)
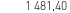 (obraz) vs 1481.4 (OCR)
(obraz) vs 1481.4 (OCR)
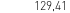 (obraz) vs 129.41 (OCR)
(obraz) vs 129.41 (OCR)
 (obraz) vs 101.11 (OCR)
(obraz) vs 101.11 (OCR)
 (obraz) vs 107.41 (OCR)
(obraz) vs 107.41 (OCR)
 (obraz) vs 104.46 (OCR)
(obraz) vs 104.46 (OCR)
 (obraz) vs 83.55 (OCR)
(obraz) vs 83.55 (OCR)
Po przeanalizowaniu kolejnych obrazków okazuje się, że to rozwiązanie ma skuteczność na poziomie 95%. Całkiem nieźle.
GOOGLE DRIVE
Do skorzystania z pakietu googledrive wystarczy posiadanie konta na Gmailu (jest ono niezbędne do autoryzacji połączenia z dyskiem Google). Zasada działania OCRa w oparciu o dysk Google jest prosta: wysyłam plik na dysk Google i konwertuję go do dokumentu Google. Następnie pobieram przekonwertowany plik w dowolnej formie (np. jako plik tekstowy).
OCRbyGoogleDrive <- function(urls) {
# pobieram obrazki do plików tymczasowych
imgs <- list()
for (url in urls) {
imgs %<>%
append(list(list(url = url,
fn = tempfile())))
}
lapply(imgs, function(x)
{image_read(x$url) %>%
image_write(x$fn, format = "png")})
# wysyłam obrazki na dysk Google
gd_imgs <-
lapply(imgs, function(x)
{drive_upload(x$fn, type = "png")})
# konwertuję obrazki na dokumenty Google
gd_imgs_cp <-
lapply(gd_imgs, function(x)
{drive_cp(as_id(x$id),
mime_type = drive_mime_type("document"))})
# zapisuję na dysku jako pliki txt
txt_files <-
lapply(gd_imgs_cp, function(x)
{drive_download(as_id(x$id), type = "txt")})
# oczyszczam wyniki
res <-
sapply(txt_files, function(x)
{read_file(x$local_path)}) %>%
stri_replace_all_regex("[ ,\\.]", "") %>%
stri_extract_last_regex("[0-9]+") %>%
as.numeric %>%
divide_by(100)
# usuwam pliki tymczasowe
imgs %>% lapply(function(x)
unlink(x$fn))
txt_files %>% lapply(function(x)
unlink(x$local_path))
gd_imgs %>% lapply(function(x)
drive_rm(as_id(x$id)))
gd_imgs_cp %>% lapply(function(x)
drive_rm(as_id(x$id)))
return(cbind(urls, res))
}Poniżej wyniki dla pierwszych dziesięciu obrazków:
(obraz) vs 1254.27 (OCR)
(obraz) vs 1959.51 (OCR)
(obraz) vs 126.72 (OCR)
(obraz) vs 104.24 (OCR)
(obraz) vs 1481.4 (OCR)
(obraz) vs 129.41 (OCR)
(obraz) vs 101.11 (OCR)
(obraz) vs 107.41 (OCR)
(obraz) vs 104.46 (OCR)
(obraz) vs 83.55 (OCR)
Jak widać problem pojawił się już na początku - niewłaściwe odczytanie wartości 9 dla drugiego obrazka. Niemniej jednak analiza wszystkich obrazków wskazuje na to, że ta metoda ma podobną skuteczność jak tesseract.
Wyniki dla obu metod okazały się dobre, ale dla większości osób będą niesatysfakcjonujące (oczekuje się skuteczności na poziomie 100%). W dalszych krokach należałoby się zastanowić nad różnymi modyfikacjami obrazków lub dodatkowymi funkcjami czyszczącymi. Możnaby także połączyć obie te metody i w przypadku, gdy obie zwracają ten sam wynik założyć, że jest on poprawny. Dla bardziej zaawansowanych, można spróbować nauczyć tesseract rozpoznawania znaków na konkretnym zbiorze danych.