Scrapy is the best and most flexible web scraping tool I’ve found so far. The speed at which scripts are created depends on the structure of the site being analyzed, the bot security used, and the amount of data downloaded. In standard cases, the creation and implementation of a web scraper can take literally 15 minutes. This entry is a short tutorial to the tool. I will show how to create a simple web scraper (on the example of a famous advertisement website) and how to use a Scrapinghub website to implement a script so that it runs cyclically.
Source code is available on my GitHub.
# Libraries:
# pip install scrapy
conda install -c conda-forge scrapy # preferred
pip install shub # scrapinghub clientWhy Scrapy?
- open source
- work on projects for which templates can be created
- extensions to bypass security measures against bots:
- user agent rotation
- proxy rotation
- browser simulation via Selenium or Splash
- user agent rotation
- easy integration with external databases
- quick and easy implementation:
- scrapyd - private server
- Scrapinghub - cloud
- scrapyd - private server
One template for the project and four spiders templates are available. Over time, you can add your templates. In this case, a huge part of the work can be replaced with just two commands (scrapy startproject and scrapy genspider).
Scrapy is a top-rated tool so that you can find more (better) tutorials on the internet. I focus on showing the creation of the project from writing the scraper to its deployment. For those interested in getting to know the tool better, I refer to the documentation.
[UPDATE - March 2020]
The entry is educational, so please use the scripts presented here with caution. Using web scraper without thinking can lead to the blocking of your IP. As a consequence, not only you but your family or coworkers may lose access to the pages you use daily (e.g., online store or announcement service). For this entry, I chose the service Otodom, but I could choose any other. As of today, this service blocks IP Scrapinghub. Therefore additional actions would be needed for full success (e.g., proxy or Crawlera integration = costs).
STEP 1. WEB SCRAPER
From the terminal level, I execute the following code:
scrapy startproject otodom_scraper
cd otodom_scraper
scrapy genspider -t crawl crawl_ads_basic otodom.plI’ve just prepared all the necessary files for work. The most interesting data are in crawl_ads_basic.py, which contains the scraper’s structure, and items.py, which includes the output structure.
+-- scrapy.cfg
+-- setup.py
+-- otodom_scraper
| +-- spiders
| +-- crawl_ads_basic.py
| +-- settings.py
| +-- items.py
| +-- middlewares.py
| +-- pipelines.pyIt is essential to use good practices when downloading content from websites. One of them is using the delay not to use the server excessively. To set the delay, use the DOWNLOAD_DELAY option available in the settings.py file.
When creating the script, I focused on downloading ads for the sale of apartments. Only the location of the flat has been parameterized (parameter locations). For location parameterization to work correctly, I wrote a function to remove diacritical marks.
def remove_diacritics(input_str):
nfkd_form = unicodedata.normalize('NFKD', input_str.replace('ł', 'l'))
return u''.join([c for c in nfkd_form if not unicodedata.combining(c)])
# remove_diacritics('zażółć gęślą jaźń')class CrawlAdsBasicSpider(CrawlSpider):
name = 'crawl_ads_basic'
allowed_domains = ['otodom.pl']
def __init__(self,
locations=None,
*args, **kwargs):
if locations:
self.locations = remove_diacritics(locations).replace(' ', '-').split(';')
self.locations = [x + '/' for x in self.locations]
else:
self.locations = ['']
url_parts = ['/sprzedaz/mieszkanie/' + x for x in self.locations]
...I chose the crawling web approach. I move on the side, defining the rules imposed on the found links. allowed_domains specifies acceptable domains from start addresses. start_urls specifies the addresses from which the search will begin. rules specify rules by which urls are selected when navigating the site. In this case, I want to browse through the pages containing a list of offers for selected locations. For each link detected, the script generates a query and forwards the response to the parse_item function.
...
self.start_urls = ['https://www.otodom.pl' + x + '?nrAdsPerPage=72' for x in url_parts]
self.rules = (
Rule(LinkExtractor(allow=[x + '\\?nrAdsPerPage=72$' for x in url_parts]),
callback='parse_item', follow=True),
Rule(LinkExtractor(allow=[x + '.*page=[0-9]+$' for x in url_parts]),
callback='parse_item', follow=True),
)I am preparing the results structure in the items.py file.
def filter_spaces(value):
return value.strip()
def clean_price(value):
return ''.join(re.findall('[0-9]+', value))
class AdItem(scrapy.Item):
item_id = scrapy.Field(
input_processor=MapCompose(filter_spaces),
output_processor=TakeFirst(),
)
tracking_id = scrapy.Field(
input_processor=MapCompose(filter_spaces),
output_processor=TakeFirst(),
)
url = scrapy.Field(
input_processor=MapCompose(filter_spaces),
output_processor=TakeFirst(),
)
featured_name = scrapy.Field(
input_processor=MapCompose(filter_spaces),
output_processor=TakeFirst(),
)
title = scrapy.Field(
input_processor=MapCompose(filter_spaces),
output_processor=TakeFirst(),
)
subtitle = scrapy.Field(
input_processor=MapCompose(filter_spaces),
output_processor=TakeFirst(),
)
rooms = scrapy.Field(
input_processor=MapCompose(filter_spaces),
output_processor=TakeFirst(),
)
price = scrapy.Field(
input_processor=MapCompose(clean_price),
output_processor=TakeFirst(),
)
price_per_m = scrapy.Field(
input_processor=MapCompose(clean_price),
output_processor=TakeFirst(),
)
area = scrapy.Field(
input_processor=MapCompose(filter_spaces),
output_processor=TakeFirst(),
)
others = scrapy.Field(
input_processor=MapCompose(filter_spaces),
output_processor=Join(),
)In very simplified: I create the AdItem class in which I define the result fields (e.g.,title as the title of the advertisement). Each of these fields can be covered with data cleaning functions. For example, if I enter the price of a flat as the list [' PLN 100,000 ',' PLN 1 '], then ‘input_processor’ will process the list to the form ['100000','1'], while ‘output_processor’ will return the result as the first on the list, i.e. '100000'.
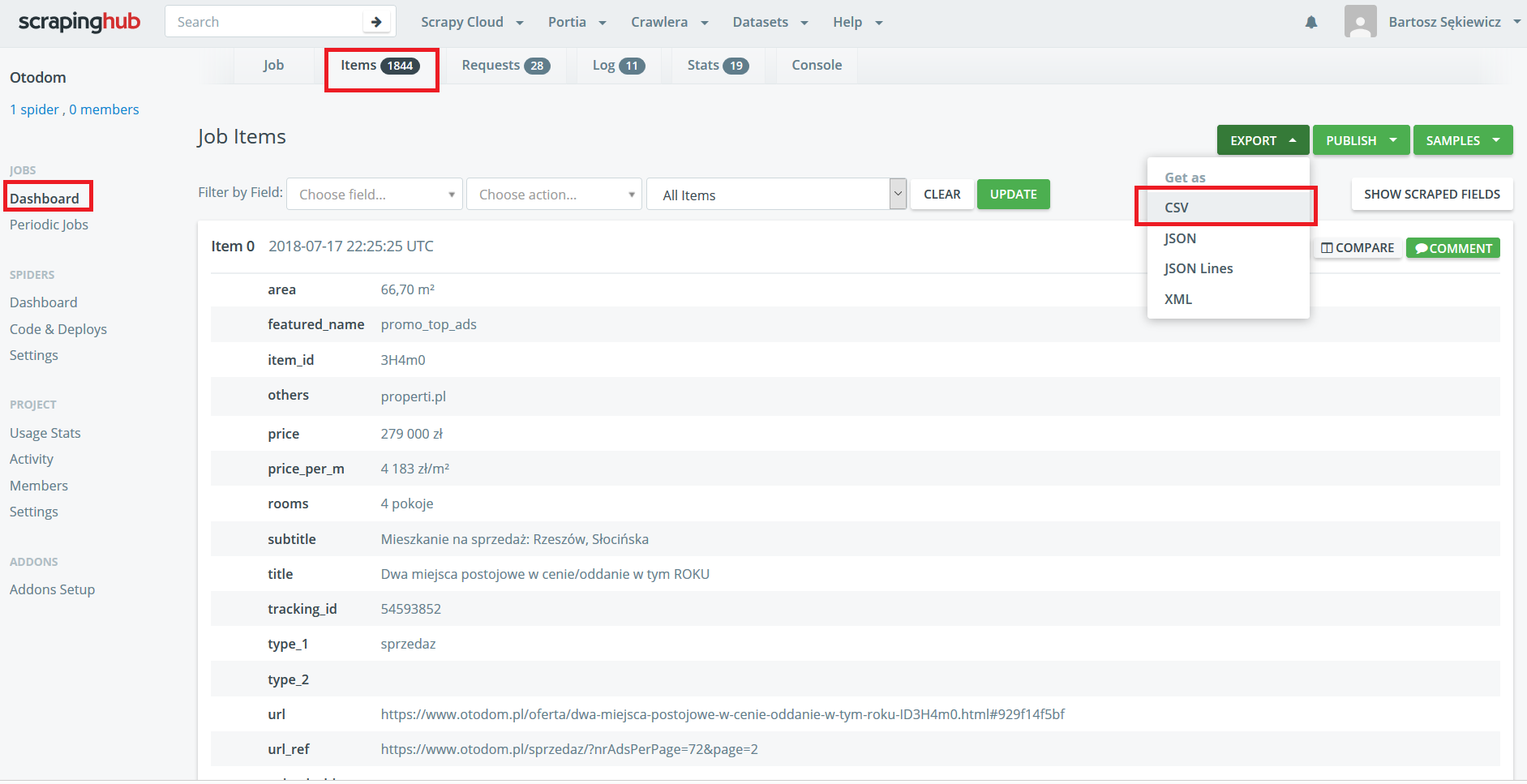
In the crawl_ads_basic.py file, the only thing left is to write a function that extracts data from the list of ads. I go through each element of the list and use the CSS selectors to get the values that interest me. I’m not worried about data cleaning, because it is already programmed in the AdItem class. The extracted data is captured by the pipeline and returned by default in the console. I recommend looking into the file settings.py - there are options to save these results as CSV, JSON, or XML files.
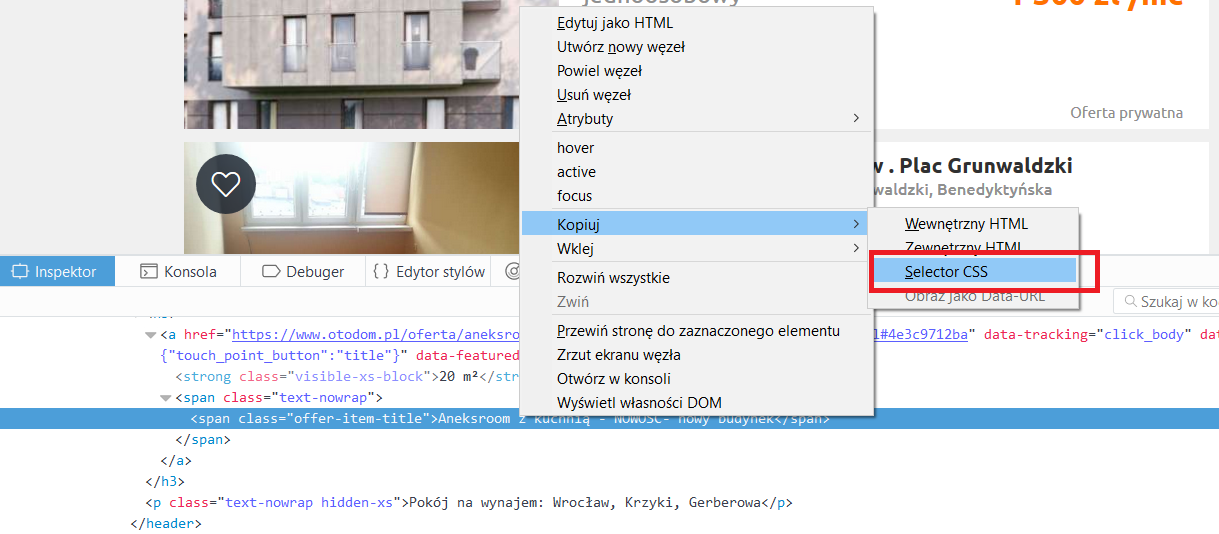
def parse_item(self, response):
for ad in response.css('.col-md-content article'):
item = ItemLoader(item=AdItem(), selector=ad)
item.add_css('item_id', '::attr("data-item-id")')
item.add_css('tracking_id', '::attr("data-tracking-id")')
item.add_css('url', '::attr("data-url")')
item.add_css('featured_name', '::attr("data-featured-name")')
item.add_css('title', '.offer-item-title ::text')
item.add_css('subtitle', '.offer-item-header p ::text')
item.add_css('rooms', '.offer-item-rooms ::text')
item.add_css('price', '.offer-item-price ::text')
item.add_css('price_per_m', '.offer-item-price-per-m ::text')
item.add_css('area', '.offer-item-area ::text')
item.add_css('others', '.params-small li ::text')
yield item.load_item()Handy is the browser tools for developers. With a few clicks, you can get information about the path to the selected item.
That’s it. The script can still be tested by entering scrapy crawl crawl_ads_basic - the downloaded data should be displayed on the console. By entering scrapy crawl crawl_ads_basic -o path_to_file, you can redirect results to the selected file (default in JSON format). To set your parameter values, use the -a switch (e.g.,: scrapy crawl crawl_ads_basic -a locations=kraków;skawina). There is a sample of the data.
STEP 2. DEPLOYMENT
It is often the case that some data must be collected reasonably regularly. Having a ready script, you can use Windows Task Manager or Linux CRON. The question is, what happens when data has to be downloaded very often? A computer running 24h/day? What about situations when there is a shortage of electricity? It is best to have private server, but it costs.
We have the ready solution named Scrapinghub! The service allows you to implement your scraper for free (unfortunately, after the changes in 2019, only one hour per month and a few days of data retention). Nevertheless, it is exaggerated for small home projects.
The script implementation process is simple. In the beginning, you need to set up an account on the site (you can do it by connecting with Google+, or GitHub). Then create a new project and generate an API key so that it is possible to send the code from the terminal.
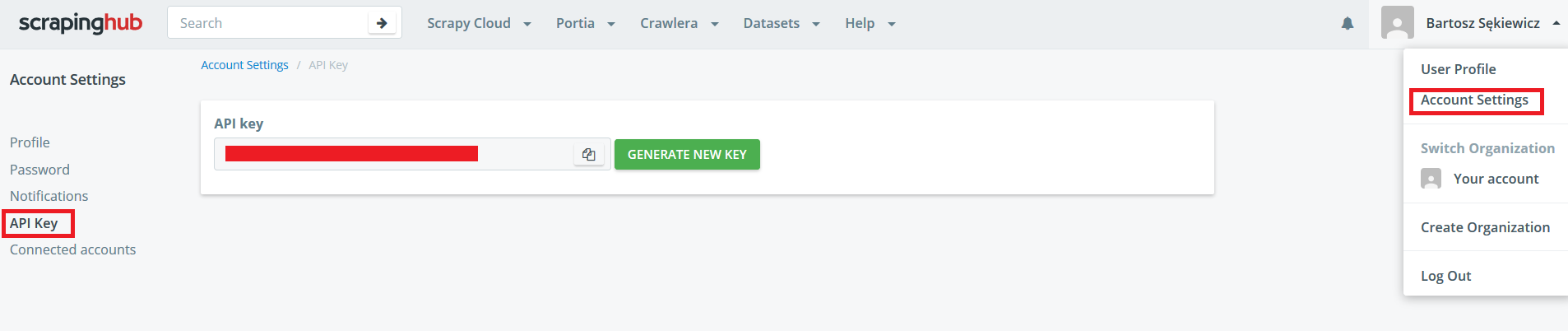
Now you can send the spider using shub library (pip install shub).
shub login
# API key: api_key
shub deploy project_idAfter a while, the script is already in the project, and you can run it!
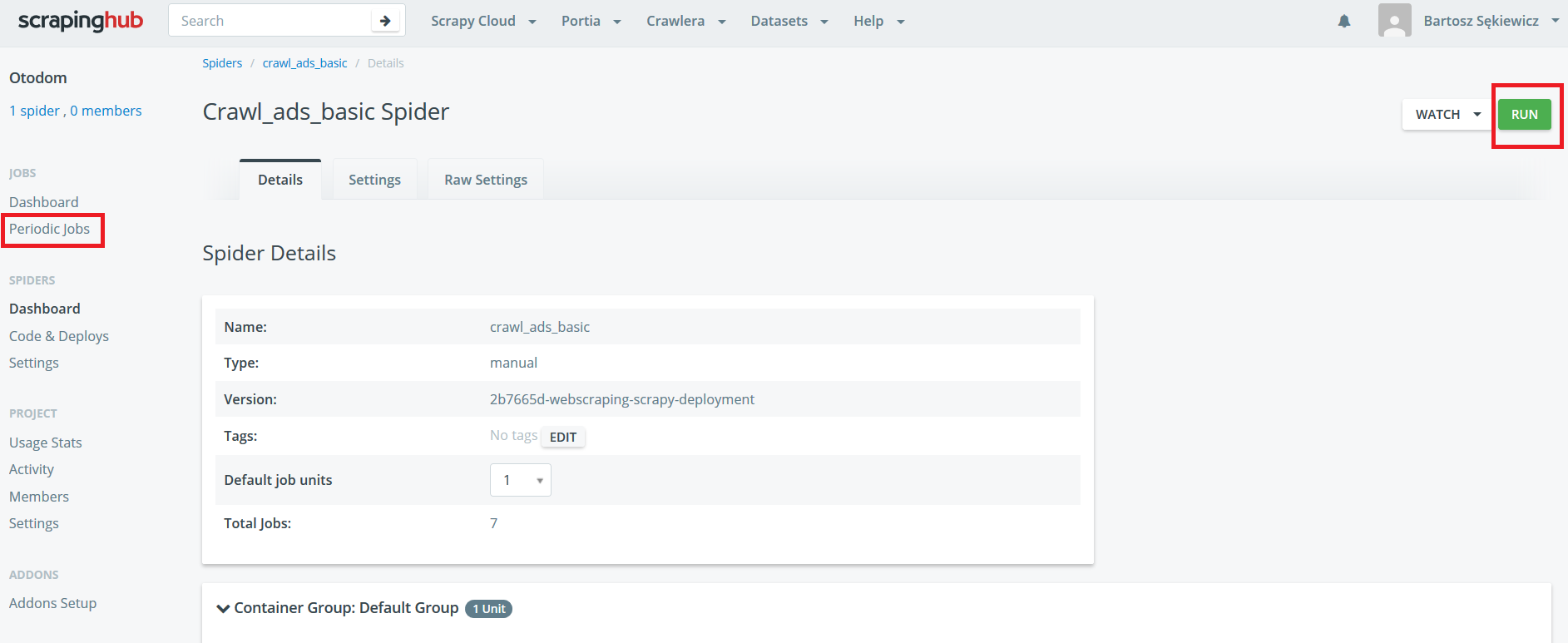
Downloading data is one click!