I’ve been doing web scraping for over three years. For this purpose, I use bash, VBA, Google Sheets, R, and Python. Recently, during the conference WhyR? 2017 and DATA SCIENCE? AGHree! 2018, I had the pleasure of leading web scraping workshops in R. During the preparation of the workshop, I came across interesting protection against automatic data downloading. In the “series” of entries regarding web scraping, I would like to share some of the problems and ideas for solving them.
Source code is available on my GitHub.
# Packages:
require(magrittr) # pipe
require(rvest) # web scraping
require(stringi) # text cleaning
require(readr) # file reading
require(magick) # image processing
require(tesseract) # OCR
require(googledrive) # Google DriveToday’s entry concerns the downloading of data in the table under this page. At first look, the problem of downloading data looks trivial. A simple table divided into several subpages. The number of results in the table can be increased to 100, while the navigation between subsequent pages is a simple parameterization of the link. The header is two-level, but that should not be a problem.
# download webpage
s <- paste0(
'https://www.analizy.pl/',
'fundusze/fundusze-inwestycyjne/notowania') %>%
html_session
# data extraction
notowania <- s %>%
# noteTable is the only element on the page
html_node("#noteTable") %>%
# the header has two levels
html_table(header = TRUE) %>%
.[,-1] %>%
set_colnames(.[1,]) %>%
# the first column is omitted (its image)
.[-1,] %T>%
# summary
str| fundusz | data | j.u..netto | X1d | X1m | X3m | X12m | X36m | X60m | ytd | grupa | srri |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AGIO Agresywny Spółek Wzrostowych (AGIO SFIO) | 3.03 | NA | 0,00% | -4,78% | -0,6% | -3,6% | -19,7% | 0,3% | -2,9% | AKP_UN | 5/7 |
| AGIO Akcji Małych i Średnich Spółek (AGIO SFIO) | 3.03 | NA | 0,00% | -3,35% | 4,7% | 2,5% | 0,7% | AKP_MS | 4/7 | ||
| AGIO Akcji PLUS (AGIO PLUS FIO) | 2.03 | NA | 2,02% | -9,40% | -8,8% | -14,0% | -28,7% | -10,2% | AKP_UN | 5/7 | |
| AGIO Dochodowy PLUS (AGIO PLUS FIO) | 2.03 | NA | -0,01% | 0,18% | 0,6% | 2,1% | 0,4% | PDP_UN | 2/7 | ||
| AGIO Kapitał (AGIO SFIO) | 3.03 | NA | 0,00% | 0,12% | 0,6% | -0,3% | 6,4% | 12,3% | 0,3% | PDP_CO | 2/7 |
I scraped almost all the data except the j.u. netto column. Why?!
…
You’re right! The values in the j.u. netto column are small images.
In the beginning, it seemed to me that the case is hopeless, i.e., I will need some advanced OCR or use of a machine learning to recognize the image. After a little research on the possibilities of R, it turned out that solutions that give good results are available without going deeper into the subject of image conversion.
I’ve tried two popular OCRs: tesseract and Google Drive. For each of these solutions, there are available libraries in R, which installation (even under Windows) is quick and friendly.
I am also scraping images links.
notowania$`j.u. netto` <- s %>%
html_nodes("tbody img[alt*='kurs']") %>%
html_attr("src") %>%
paste0("https://www.analizy.pl", .)TESSERACT
This package is available on the GitHub. You can use a standard install.packages("tesseract"). Additional libraries need to be installed under Linux, but everything is explained in the source.
# OCR settings
engine <-
tesseract(options =
list(tessedit_char_whitelist = " 0123456789,.",
tessedit_char_blacklist = "!?@#$%&*()<>_-+=/:;'\"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz\n\t\r",
classify_bln_numeric_mode = "1"))
# text cleaning
text_clearing <- function(x) {
x %>%
stri_replace_all_regex("[ \n]", "") %>%
stri_replace_all_regex("[,]+", ".") %>%
stri_extract_first_regex('[0-9]+[//.]{0,1}[0-9]{0,2}') %>%
as.numeric %>%
format(2)
}# sample conversion
notowania[['j.u. netto']][1] %>%
image_read %>%
ocr(engine) %>%
text_clearing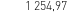 (obraz) vs 1254.97 (OCR)
(obraz) vs 1254.97 (OCR)
IT WORKS!!!
[UPDATE - March 2020]
When I published this post in 2018, the tesseract library did not work as well as it does now. To get good results, you needed to resize the image (by 30%) using the image_resize function from the magick library. As you can see, this tool is constantly being improved (but it’s still not perfect).
Below are the results for the first ten images:
(obraz) vs 1254.97 (OCR)
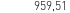 (obraz) vs 959.51 (OCR)
(obraz) vs 959.51 (OCR)
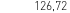 (obraz) vs 126.72 (OCR)
(obraz) vs 126.72 (OCR)
 (obraz) vs 104.24 (OCR)
(obraz) vs 104.24 (OCR)
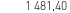 (obraz) vs 1481.4 (OCR)
(obraz) vs 1481.4 (OCR)
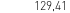 (obraz) vs 129.41 (OCR)
(obraz) vs 129.41 (OCR)
 (obraz) vs 101.11 (OCR)
(obraz) vs 101.11 (OCR)
 (obraz) vs 107.41 (OCR)
(obraz) vs 107.41 (OCR)
 (obraz) vs 104.46 (OCR)
(obraz) vs 104.46 (OCR)
 (obraz) vs 83.55 (OCR)
(obraz) vs 83.55 (OCR)
After analyzing all the pictures, it turns out that this solution has an efficiency of 95%. Pretty good.
GOOGLE DRIVE
To use the googledrive package, you only need to have a Gmail account (it is necessary to authorize the connection with Google Drive). The principle of OCR based on Google disk is simple: I send a file to a Google disk and convert it to a Google document. Then I download the converted file in any form (e.g., as a text file).
OCRbyGoogleDrive <- function(urls) {
# download images
imgs <- list()
for (url in urls) {
imgs %<>%
append(list(list(url = url,
fn = tempfile())))
}
lapply(imgs, function(x)
{image_read(x$url) %>%
image_write(x$fn, format = "png")})
# send images to Google Drive
gd_imgs <-
lapply(imgs, function(x)
{drive_upload(x$fn, type = "png")})
# convert to Google documents
gd_imgs_cp <-
lapply(gd_imgs, function(x)
{drive_cp(as_id(x$id),
mime_type = drive_mime_type("document"))})
# write as txt files
txt_files <-
lapply(gd_imgs_cp, function(x)
{drive_download(as_id(x$id), type = "txt")})
# text cleaning
res <-
sapply(txt_files, function(x)
{read_file(x$local_path)}) %>%
stri_replace_all_regex("[ ,\\.]", "") %>%
stri_extract_last_regex("[0-9]+") %>%
as.numeric %>%
divide_by(100)
# remove temporary files
imgs %>% lapply(function(x)
unlink(x$fn))
txt_files %>% lapply(function(x)
unlink(x$local_path))
gd_imgs %>% lapply(function(x)
drive_rm(as_id(x$id)))
gd_imgs_cp %>% lapply(function(x)
drive_rm(as_id(x$id)))
return(cbind(urls, res))
}Below are the results for the first ten images:
(obraz) vs 1254.27 (OCR)
(obraz) vs 1959.51 (OCR)
(obraz) vs 126.72 (OCR)
(obraz) vs 104.24 (OCR)
(obraz) vs 1481.4 (OCR)
(obraz) vs 129.41 (OCR)
(obraz) vs 101.11 (OCR)
(obraz) vs 107.41 (OCR)
(obraz) vs 104.46 (OCR)
(obraz) vs 83.55 (OCR)
In this case, the problem appeared already in the first ten results - incorrect reading of the value 9 for the second image. However, the analysis of all images indicates that OCR by Google Drive has similar efficacy as a tesseract.
The results in both cases proved to be quite good, but unsatisfactory (I expect 100% effectiveness). In the next steps, you would have to think about other image modifications or additional cleaning functions. Alternatively, you can combine both methods. For more advanced users, you can try teaching tesseract to recognize characters on a specific data set.